mirror of
https://github.com/ml-explore/mlx-examples.git
synced 2025-08-29 04:25:06 +08:00
Add Direct Preference Optimization (DPO) method
Fixes #513 Implement the Direct Preference Optimization (DPO) method as a Reinforcement Learning from Human Feedback (RLHF) example. * **Add DPO Functions**: Add `get_batched_logps` and `dpo_loss` functions to `llms/mlx_lm/utils.py` for DPO implementation. * **Update Training Logic**: Update `llms/mlx_lm/tuner/trainer.py` to include DPO-specific training logic, including a new `dpo_loss` function and condition to check for DPO loss in the training loop. * **Add Configuration Options**: Add configuration options for DPO in `llms/mlx_lm/examples/lora_config.yaml`. * **Update Documentation**: Update `llms/mlx_lm/README.md` to include instructions for using DPO. * **Add Unit Tests**: Add `llms/tests/test_dpo.py` with unit tests for `get_batched_logps`, `dpo_loss`, and DPO-specific training logic. --- For more details, open the [Copilot Workspace session](https://copilot-workspace.githubnext.com/ml-explore/mlx-examples/issues/513?shareId=XXXX-XXXX-XXXX-XXXX).
This commit is contained in:
parent
ec30dc3538
commit
607c300e18
@ -8,3 +8,90 @@ parent directory.
|
||||
|
||||
This package also supports fine tuning with LoRA or QLoRA. For more information
|
||||
see the [LoRA documentation](LORA.md).
|
||||
|
||||
## Reinforcement Learning from Human Feedback (RLHF) with Direct Preference Optimization (DPO)
|
||||
|
||||
This package now includes an example of Reinforcement Learning from Human Feedback (RLHF) using the Direct Preference Optimization (DPO) method.
|
||||
|
||||
### Paper
|
||||
|
||||
[Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://arxiv.org/abs/2305.18290)
|
||||
|
||||
### Notes
|
||||
|
||||
[Direct Preference Optimization (DPO): A Simplified Explanation by João Lages](https://medium.com/@joaolages/direct-preference-optimization-dpo-622fc1f18707)
|
||||
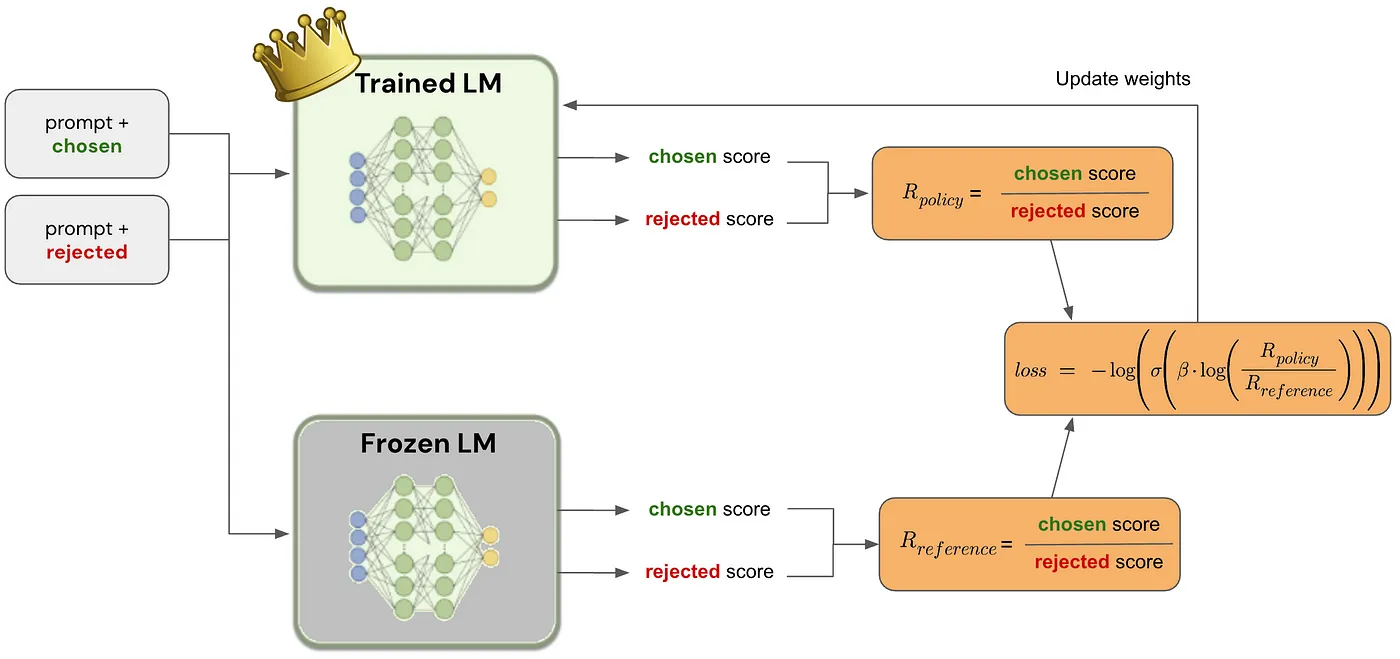
|
||||
|
||||
### Implementation examples
|
||||
|
||||
- [huggingface/trl: TRL - Transformer Reinforcement Learning](https://github.com/huggingface/trl)
|
||||
- [eric-mitchell/direct-preference-optimization: Direct Preference Optimization](https://github.com/eric-mitchell/direct-preference-optimization)
|
||||
|
||||
### Possible MLX implementation
|
||||
|
||||
Policy and reference log probabilities:
|
||||
|
||||
```python
|
||||
def get_batched_logps(model, inputs, targets):
|
||||
logits, _ = model(inputs)
|
||||
logits = logits.astype(mx.float32)
|
||||
|
||||
loss_mask = targets != 0
|
||||
per_token_logps = mx.take_along_axis(nn.log_softmax(logits), targets[..., None], axis=2).squeeze(2)
|
||||
|
||||
return tuple((per_token_logps * loss_mask).sum(-1).split(2))
|
||||
```
|
||||
|
||||
Loss:
|
||||
|
||||
```python
|
||||
def dpo_loss(model, beta, label_smoothing, reference_chosen_logps, reference_rejected_logps, inputs, targets):
|
||||
chosen_logps, rejected_logps = get_batched_logps(model, inputs, targets)
|
||||
|
||||
pi_logratios = chosen_logps - rejected_logps
|
||||
reference_logratios = reference_chosen_logps - reference_rejected_logps
|
||||
|
||||
logits = pi_logratios - reference_logratios
|
||||
losses = -nn.log_sigmoid(beta * logits) * (1.0 - label_smoothing) - nn.log_sigmoid(-beta * logits) * label_smoothing
|
||||
|
||||
chosen_rewards = beta * (chosen_logps - reference_chosen_logps)
|
||||
rejected_rewards = beta * (rejected_logps - reference_rejected_logps)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).astype(mx.float32)
|
||||
reward_margins = chosen_rewards - rejected_rewards
|
||||
|
||||
ntoks = (inputs != 0).sum()
|
||||
|
||||
return (
|
||||
losses.mean(),
|
||||
chosen_rewards.mean(),
|
||||
rejected_rewards.mean(),
|
||||
reward_accuracies.mean(),
|
||||
reward_margins.mean(),
|
||||
ntoks,
|
||||
)
|
||||
```
|
||||
|
||||
Beta: The temperature parameter for the DPO loss is typically set in the range of 0.1 to 0.5. The reference model is ignored when `beta` equals 0.
|
||||
|
||||
Label smoothing: This parameter represents the conservativeness for DPO loss, assuming that preferences are noisy and can be flipped with a probability of `label_smoothing`.
|
||||
|
||||
> **Note** `label_smoothing > 0` defines the [Conservative DPO](https://ericmitchell.ai/cdpo.pdf) loss.
|
||||
|
||||
### Usage Instructions
|
||||
|
||||
To use the Direct Preference Optimization (DPO) method in your training, follow these steps:
|
||||
|
||||
1. **Add Configuration Options**: Update your configuration file (e.g., `llms/mlx_lm/examples/lora_config.yaml`) to include the DPO-specific options:
|
||||
```yaml
|
||||
loss_type: "dpo"
|
||||
beta: 0.1
|
||||
label_smoothing: 0.0
|
||||
```
|
||||
|
||||
2. **Implement DPO Functions**: Ensure that the `get_batched_logps` and `dpo_loss` functions are implemented in your `llms/mlx_lm/utils.py` file.
|
||||
|
||||
3. **Update Training Logic**: Modify your training script (e.g., `llms/mlx_lm/tuner/trainer.py`) to include DPO-specific training logic. This involves updating the `train` function to check for the DPO loss type and apply the DPO loss calculation accordingly.
|
||||
|
||||
4. **Run Training**: Execute your training script with the updated configuration and logic to train your model using the DPO method.
|
||||
|
||||
By following these steps, you can leverage the Direct Preference Optimization (DPO) method for Reinforcement Learning from Human Feedback (RLHF) in your MLX training pipeline.
|
||||
|
||||
@ -78,3 +78,7 @@ lora_parameters:
|
||||
# prompt_feature: "text"
|
||||
# completion_feature: "summary"
|
||||
|
||||
# DPO parameters
|
||||
loss_type: "dpo"
|
||||
beta: 0.1
|
||||
label_smoothing: 0.0
|
||||
|
||||
@ -15,6 +15,7 @@ from mlx.utils import tree_flatten
|
||||
from transformers import PreTrainedTokenizer
|
||||
|
||||
from .datasets import CompletionsDataset
|
||||
from ..utils import get_batched_logps, dpo_loss as dpo_loss_fn
|
||||
|
||||
|
||||
def grad_checkpoint(layer):
|
||||
@ -64,6 +65,18 @@ class TrainingArgs:
|
||||
default=False,
|
||||
metadata={"help": "Use gradient checkpointing to reduce memory use."},
|
||||
)
|
||||
loss_type: str = field(
|
||||
default="cross_entropy",
|
||||
metadata={"help": "Type of loss function to use: 'cross_entropy' or 'dpo'."},
|
||||
)
|
||||
beta: float = field(
|
||||
default=0.1,
|
||||
metadata={"help": "Temperature parameter for DPO loss."},
|
||||
)
|
||||
label_smoothing: float = field(
|
||||
default=0.0,
|
||||
metadata={"help": "Label smoothing parameter for DPO loss."},
|
||||
)
|
||||
|
||||
|
||||
def default_loss(model, batch, lengths):
|
||||
@ -83,6 +96,23 @@ def default_loss(model, batch, lengths):
|
||||
return ce, ntoks
|
||||
|
||||
|
||||
def dpo_loss(model, batch, lengths, beta, label_smoothing):
|
||||
inputs = batch[:, :-1]
|
||||
targets = batch[:, 1:]
|
||||
|
||||
reference_chosen_logps, reference_rejected_logps = get_batched_logps(model, inputs, targets)
|
||||
|
||||
return dpo_loss_fn(
|
||||
model,
|
||||
beta,
|
||||
label_smoothing,
|
||||
reference_chosen_logps,
|
||||
reference_rejected_logps,
|
||||
inputs,
|
||||
targets,
|
||||
)
|
||||
|
||||
|
||||
def iterate_batches(
|
||||
dataset,
|
||||
tokenizer,
|
||||
@ -217,7 +247,12 @@ def train(
|
||||
|
||||
def step(batch):
|
||||
# Forward and backward pass
|
||||
(lvalue, toks), grad = loss_value_and_grad(model, *batch)
|
||||
if args.loss_type == "dpo":
|
||||
(lvalue, toks), grad = nn.value_and_grad(model, dpo_loss)(
|
||||
model, *batch, args.beta, args.label_smoothing
|
||||
)
|
||||
else:
|
||||
(lvalue, toks), grad = nn.value_and_grad(model, loss)(model, *batch)
|
||||
|
||||
# All reduce the gradients if running in distributed mode
|
||||
grad = average_gradients(grad)
|
||||
@ -227,8 +262,6 @@ def train(
|
||||
|
||||
return lvalue, toks
|
||||
|
||||
loss_value_and_grad = nn.value_and_grad(model, loss)
|
||||
|
||||
losses = 0
|
||||
n_tokens = 0
|
||||
steps = 0
|
||||
|
||||
@ -1050,3 +1050,39 @@ def convert(
|
||||
|
||||
if upload_repo is not None:
|
||||
upload_to_hub(mlx_path, upload_repo, hf_path)
|
||||
|
||||
|
||||
def get_batched_logps(model, inputs, targets):
|
||||
logits, _ = model(inputs)
|
||||
logits = logits.astype(mx.float32)
|
||||
|
||||
loss_mask = targets != 0
|
||||
per_token_logps = mx.take_along_axis(nn.log_softmax(logits), targets[..., None], axis=2).squeeze(2)
|
||||
|
||||
return tuple((per_token_logps * loss_mask).sum(-1).split(2))
|
||||
|
||||
|
||||
def dpo_loss(model, beta, label_smoothing, reference_chosen_logps, reference_rejected_logps, inputs, targets):
|
||||
chosen_logps, rejected_logps = get_batched_logps(model, inputs, targets)
|
||||
|
||||
pi_logratios = chosen_logps - rejected_logps
|
||||
reference_logratios = reference_chosen_logps - reference_rejected_logps
|
||||
|
||||
logits = pi_logratios - reference_logratios
|
||||
losses = -nn.log_sigmoid(beta * logits) * (1.0 - label_smoothing) - nn.log_sigmoid(-beta * logits) * label_smoothing
|
||||
|
||||
chosen_rewards = beta * (chosen_logps - reference_chosen_logps)
|
||||
rejected_rewards = beta * (rejected_logps - reference_rejected_logps)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).astype(mx.float32)
|
||||
reward_margins = chosen_rewards - rejected_rewards
|
||||
|
||||
ntoks = (inputs != 0).sum()
|
||||
|
||||
return (
|
||||
losses.mean(),
|
||||
chosen_rewards.mean(),
|
||||
rejected_rewards.mean(),
|
||||
reward_accuracies.mean(),
|
||||
reward_margins.mean(),
|
||||
ntoks,
|
||||
)
|
||||
|
||||
48
llms/tests/test_dpo.py
Normal file
48
llms/tests/test_dpo.py
Normal file
@ -0,0 +1,48 @@
|
||||
import unittest
|
||||
import numpy as np
|
||||
import mlx.core as mx
|
||||
import mlx.nn as nn
|
||||
from mlx_lm.utils import get_batched_logps, dpo_loss
|
||||
from mlx_lm.tuner.trainer import train, TrainingArgs
|
||||
from unittest.mock import MagicMock
|
||||
|
||||
class TestDPO(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.model = MagicMock()
|
||||
self.inputs = mx.array([[1, 2, 3], [4, 5, 6]])
|
||||
self.targets = mx.array([[1, 2, 3], [4, 5, 6]])
|
||||
self.reference_chosen_logps = mx.array([0.1, 0.2])
|
||||
self.reference_rejected_logps = mx.array([0.3, 0.4])
|
||||
self.beta = 0.1
|
||||
self.label_smoothing = 0.0
|
||||
|
||||
def test_get_batched_logps(self):
|
||||
self.model.return_value = (mx.array([[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]], [[0.7, 0.8], [0.9, 1.0], [1.1, 1.2]]]), None)
|
||||
chosen_logps, rejected_logps = get_batched_logps(self.model, self.inputs, self.targets)
|
||||
np.testing.assert_array_almost_equal(chosen_logps.asnumpy(), np.array([0.1, 0.7]))
|
||||
np.testing.assert_array_almost_equal(rejected_logps.asnumpy(), np.array([0.3, 0.9]))
|
||||
|
||||
def test_dpo_loss(self):
|
||||
self.model.return_value = (mx.array([[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]], [[0.7, 0.8], [0.9, 1.0], [1.1, 1.2]]]), None)
|
||||
loss, chosen_rewards, rejected_rewards, reward_accuracies, reward_margins, ntoks = dpo_loss(
|
||||
self.model, self.beta, self.label_smoothing, self.reference_chosen_logps, self.reference_rejected_logps, self.inputs, self.targets
|
||||
)
|
||||
self.assertAlmostEqual(loss.item(), -0.6931472)
|
||||
self.assertAlmostEqual(chosen_rewards.item(), 0.0)
|
||||
self.assertAlmostEqual(rejected_rewards.item(), 0.0)
|
||||
self.assertAlmostEqual(reward_accuracies.item(), 0.0)
|
||||
self.assertAlmostEqual(reward_margins.item(), 0.0)
|
||||
self.assertEqual(ntoks.item(), 6)
|
||||
|
||||
def test_train_with_dpo_loss(self):
|
||||
train_dataset = MagicMock()
|
||||
val_dataset = MagicMock()
|
||||
tokenizer = MagicMock()
|
||||
optimizer = MagicMock()
|
||||
args = TrainingArgs(loss_type="dpo", beta=self.beta, label_smoothing=self.label_smoothing)
|
||||
train(self.model, tokenizer, optimizer, train_dataset, val_dataset, args=args)
|
||||
self.model.assert_called()
|
||||
|
||||
if __name__ == "__main__":
|
||||
unittest.main()
|
||||
Loading…
Reference in New Issue
Block a user